Duplicate Monitoring (supported by Duplicate Guard) provides a robust solution for continuously identifying and managing potential duplicates within a data mirror. The system automatically monitors new and updated records for duplicates using a predefined matching configuration. This process involves searching for potential duplicate candidates, assessing their similarity, and storing the results in a database that tracks relationships between records (in other words - a link database which stores information about linked records - duplicated ones).
When Duplicate Monitoring is activated, the system conducts an initial scan of all records, storing any identified duplicates in the form of links. Each link is created between a pattern (Business Partner record) and a potential (based on the matching configuration) duplicate in order to correlate those two records. Ongoing monitoring ensures that new or updated records trigger the matching process, where potential duplicates are evaluated and linked accordingly. If a record changes and invalidates a previous duplicate match, the link is automatically updated or removed.
The system allows for detailed analysis of identified duplicates, enabling users to retrieve and filter links based on confidence levels and status. Additionally, the creation of matching groups helps cluster records that represent the same entity, offering insights into the extent of duplication and supporting data cleanup efforts.
By automating the detection and management of duplicates, Duplicate Monitoring reduces manual intervention, ensuring cleaner and more reliable datasets. The feature integrates seamlessly into the broader data management workflow, helping businesses maintain data integrity with minimal effort.
Available in:
Entity Matching LinksAPI endpoint:/entityresolution/entitymatchinglinks
Across whole articles you can find clickable links to endpoint like this: /entityresolution/entitymatchinglinks. After click you will be redirected to the detailed API reference documentation.
- Data Clinic Reports (UI) for aggregated, user-friendly views
Duplicate Monitoring runs automatically according to the given configuration. Initial scans can be large, and ongoing changes trigger re-evaluation automatically; manual review remains optional but supported.
Duplicate Monitoring continuously supervises a data mirror for duplicates and provides an always up-to-date overview of identified matches. Users activate monitoring by selecting which data sources are considered in the matching (deduplication) process and by supplying a duplicate matching configuration. Upon activation, all records in the selected sources are scanned. New or changed records in the Data Mirror trigger matching for those records only: cleaners are applied, candidates are searched, and then compared. Resulting potential duplicates are preserved. If the matching configuration is changed or replaced, the Link Database is cleared except for links that were manually reviewed (links with status ASSERTED or RETRACTED). Matching is then re-executed for all monitored records.
Manually reviewed links (ASSERTED or RETRACTED) persist across configuration changes. Only INFERRED links are removed when the matching configuration changes.
The results of the matching process for each record are stored as new or changed links. Link reliability is categorized as follows:
| Status | Description |
|---|---|
INFERRED | Identified by the algorithm based on the configured matching logic and thresholds. Only MATCH and MAYBE_MATCH links are stored. |
ASSERTED | Confirmed correct based on outside evidence, currently via manual duplicate reviews. These links are not removed when the matching configuration changes (as well as RETRACTED ones). |
RETRACTED | Confirmed incorrect based on outside evidence, currently via manual duplicate reviews. |
When an existing record is updated by the user this may lead to the situation that links that were once identified are no longer valid and/or that new links are found. If there are links that were once INFERRED but do not exist after the update, the links are completely removed from the Links Database. Manually reviewed links are not changed (ASSERTED or RETRACTED).
For now, users can read and filter the links for a given record using this API endpoint: /entityresolution/entitymatchinglinks. Nevertheless, the best way to view the whole picture (all Business Partners with attributes) is to generate reports using Data Clinic Reports.
Check the How to set up and activate Duplicate Guard Monitor tutorial to generate report.
In the Data Clinic application users can activate a Duplicate Guard Monitor and generate reports in the Reports tab. However, in order to run any monitor the proper configuration needs to be set. In case of Duplicate Guard a user needs to generate (and adjust if necessary) the default configuration in the Duplicate Guard Configurator application. This default configuration is designed to systematically identify duplicate records based on specified attributes and matching criteria, using various cleaning and comparison techniques to ensure accuracy.
The example Duplicate Guard Matching configuration is presented below:
{
"name": "Default Matching Configuration",
"configuration": {
"candidateSearchConfiguration": {
"maxCandidates": 10,
"searchAttributes": [
{
"jsonPath": "$.names[0].value"
},
{
"jsonPath": "$.addresses[0].country.shortName"
},
{
"jsonPath": "$.addresses[0].thoroughfares[0].value"
}
]
},
"generalMatchingConfiguration": {
"threshold": 0.85,
"thresholdMaybe": 0.65,
"matchingAttributes": [
{
"name": "Business Partner Name",
"jsonPath": "businessPartner.names[0].value",
"cleaners": [
{
"name": "LowerCaseNormalizer"
},
{
"name": "PunctuationsCleaner"
},
{
"name": "LegalFormCleaner",
"parameters": [
{
"name": "configProperty",
"value": "$.addresses[0].country.shortName"
}
]
}
],
"high": 0.8,
"low": 0.3,
"comparator": {
"name": "QGramComparator",
"parameters": [
{
"name": "tokenizer",
"value": "BASIC"
},
{
"name": "formula",
"value": "DICE"
},
{
"name": "q",
"value": "3"
}
]
}
},
{
"name": "Business Partner Country",
"jsonPath": "businessPartner.addresses[0].country.shortName",
"cleaners": [
{
"name": "LowerCaseNormalizer"
}
],
"high": 0.5,
"low": 0,
"comparator": {
"name": "ExactComparator"
}
},
{
"name": "Business Partner City",
"jsonPath": "businessPartner.addresses[0].localities[0].value",
"cleaners": [
{
"name": "LowerCaseNormalizer"
},
{
"name": "PunctuationsCleaner"
}
],
"high": 0.6,
"low": 0.2,
"comparator": {
"name": "Levenshtein"
}
},
{
"name": "Business Partner Street",
"jsonPath": "businessPartner.addresses[0].thoroughfares[0].value",
"cleaners": [
{
"name": "LowerCaseNormalizer"
},
{
"name": "PunctuationsCleaner"
}
],
"high": 0.7,
"low": 0.3,
"comparator": {
"name": "Levenshtein"
}
},
{
"name": "Business Partner Postal Code",
"jsonPath": "businessPartner.addresses[0].postCodes[0].value",
"cleaners": [
{
"name": "DigitsOnlyCleaner"
}
],
"high": 0.6,
"low": 0.3,
"comparator": {
"name": "ExactComparator"
}
}
]
},
"scopedMatchingConfiguration": {}
}
}The structure of the configuration contains the following objects:
candidateSearchConfiguration: this section defines how candidate records are searched for potential duplicates. It includes:"maxCandidates": 10: specifies the maximum number of candidate records to consider (in this case it is 10)."searchAttributes": defines the attributes used to search for candidates. Each defined by a JSON path:{"jsonPath": "$.names[0].value"}: searches using the first name value.{"jsonPath": "$.addresses[0].country.shortName"}: searches using the country ISO code in the first address.{"jsonPath": "$.addresses[0].thoroughfares[0].value"}: searches using the thoroughfare value in the first address.
- It is worth noting that the selection of Business Partner attributes is fully conformant with RFC 9535.
generalMatchingConfiguration: defines the criteria for matching records:"threshold": 0.85: is the score above which records are considered a definite match."thresholdMaybe": 0.65: is the score above which records are considered a possible match but lower than the"threshold"value. The range in this case is ("thresholdMaybe","threshold")."matchingAttributes": describes the attributes used for matching:"name": is the descriptive name of the attribute being matched. This name appears in reports."jsonPath": points to the attribute in the JSON structure."cleaners": lists the cleaning operations applied before matching (for example,LowerCaseNormalizer,PunctuationsCleaner)."high"and"low": are thresholds for matching scores specific to the attribute."comparator": is the method used to compare the attribute values (for example,QGramComparator,ExactComparator,Levenshtein).
scopedMatchingConfiguration: this section defines the criteria for matching records in a similar way as thegeneralMatchingConfigurationsection. However, in this case we have an additional field:"scope": indicates the country code of Business Partners that will be taken into consideration during the deduplication process. In an edge case we can imagine creating onescopedMatchingConfigurationper country, but the best practice is to create onegeneralMatchingConfigurationfor all countries and a fewscopedMatchingConfiguration: objects to indicate special approaches (like for Chinese Business Partners).
In each of above sections we can set different fields like search attributes, attribute paths, algorithm names with their options and cleaners. All those elements are provided in the API responses and will be extended in future. Currently supported comparison algorithms are included in the "Available Comparators" appendix while the list of allowed cleaners in the appendix titled "Available Cleaners". Moreover, the lists of search attributes and attribute paths are available in "Available Search Attributes" and "Available Attribute Paths for Comparators" appendixes, respectively.
Each Duplicate Guard Configuration is validated when a user wants to create or modify it. As a result an error message will be returned with insights explaining which attribute is invalid. Nevertheless, we are not validating if a regular expression is correct or not since this is almost impossible without knowing example data as well as user-oriented purpose. In case of having troubles with proper regular expressions we recommend to contact CDQ employees or rely on the results available in some well-known regex web sites.
Each Duplicate Guard Monitor relies on only one Duplicate Guard Configuration. The default behaviour for Duplicate Guard Monitor is that it is driven by the configuration in the following way:
- based on the
candidateSearchConfigurationsection candidates are searched across all data sources that monitor applies to, - if the the country iso code is included in one of
scopedMatchingConfigurationobjects then this comparison configuration is applied, - otherwise, the configuration from the
generalMatchingConfigurationsection is employed.
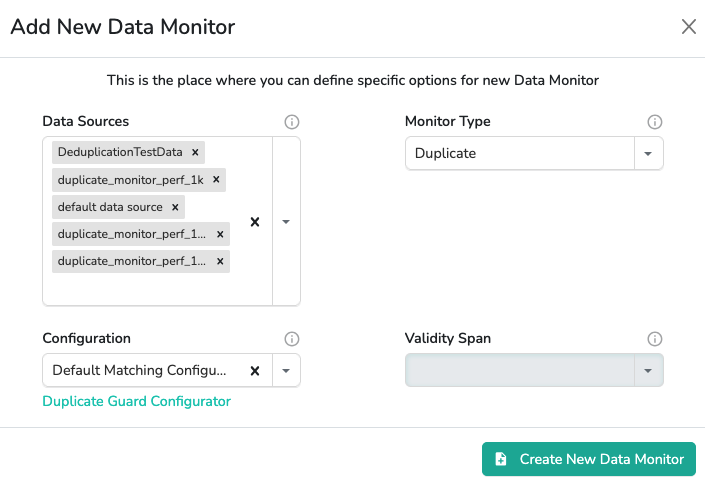
In order to start using Duplicate Guard Monitor in Data Clinic we need to provide:
- monitor type:
Duplicate - duplicate matching configuration
- data sources
For a step-by-step guide, see the tutorial: How to set up and activate Duplicate Guard Monitor. Nevertheless, the example view of Duplicate Guard Monitor creation is depicted in Figure 1.
In this section we will focus on API response. However, the best way to analyse results is to use Data Clinic in order to generate user-friendly reports.
The below example was obtained using the following endpoint: /entityresolution/entitymatchinglinks.
https://api.cdq.com/entityresolution/entitymatchinglinks?limit=200&externalId=4711&matchingScore=0.01&dataMonitorId=6842de1a29c164433a09cd1bIn the above request we need to provide Business Partner externalID value, limit of the results per page value (200 in this case), matching score above which we want to obtain the results (0.01) as well as id of the monitor (6842de1a29c164433a09cd1b). As a response we should get the results in the JSON format which should look like the following data:
{
"status": {
"code": 200,
"technicalKey": "OK",
"details": [
{
"id": 200000000,
"message": "Successful request.",
"technicalKey": "DEFAULT_OK",
"jsonRecord": {}
}
]
},
"limit": 200,
"values": [
{
"id": "6888c42ded4e327883235a4c",
"storageId": "a431da03549835d58ccf9547da32f8b5",
"dataMonitorId": "6842de1a29c164433a09cd1b",
"createdAt": "2025-07-29T12:53:01.654Z",
"createdBy": "jaroslawbak",
"modifiedAt": "2025-07-29T12:53:01.654Z",
"entityA": {
"dataSourceId": "682c39c4c28ea86749d16cc9",
"businessPartnerId": "682c3b069f8cb21410b15ba8",
"externalId": "5712"
},
"entityB": {
"dataSourceId": "682c39c4c28ea86749d16cc9",
"businessPartnerId": "682c3b069f8cb21410b15ba9",
"externalId": "57121"
},
"confidence": {
"overallScore": 0.8444444444444444,
"status": "MAYBE_MATCH",
"explanation": {
"attributeMatchingExplanation": [
{
"jsonPath": "businessPartner.addresses[0].country.shortName",
"valueA": "de",
"valueB": "de",
"similarity": 0.5
},
{
"jsonPath": "businessPartner.names[0].value",
"valueA": "volkswagen vw",
"valueB": "volks wagen",
"similarity": 0.608
},
{
"jsonPath": "businessPartner.addresses[0].thoroughfares[0].value",
"valueA": "berliner ring 2",
"valueB": "berliner ring 2",
"similarity": 0.7
},
{
"jsonPath": "businessPartner.addresses[0].localities[0].value",
"valueA": "wolfsburg",
"valueB": "wolfsburg",
"similarity": 0.6
}
]
}
},
"linkStatus": "INFERRED"
},
{
"id": "6888c42ded4e327883235a4d",
"storageId": "a431da03549835d58ccf9547da32f8b5",
"dataMonitorId": "6842de1a29c164433a09cd1b",
"createdAt": "2025-07-29T12:53:01.655Z",
"createdBy": "jaroslawbak",
"modifiedAt": "2025-07-29T12:53:01.655Z",
"entityA": {
"dataSourceId": "682c39c4c28ea86749d16cc9",
"businessPartnerId": "682c3b069f8cb21410b15b9e",
"externalId": "4711"
},
"entityB": {
"dataSourceId": "682c39c4c28ea86749d16cc9",
"businessPartnerId": "682c3b069f8cb21410b15ba1",
"externalId": "47113"
},
"confidence": {
"overallScore": 0.9450000000000001,
"status": "MATCH",
"explanation": {
"attributeMatchingExplanation": [
{
"jsonPath": "businessPartner.addresses[0].postCodes[0].value",
"valueA": "9008",
"valueB": "9008",
"similarity": 0.6
},
{
"jsonPath": "businessPartner.addresses[0].country.shortName",
"valueA": "ch",
"valueB": "ch",
"similarity": 0.5
},
{
"jsonPath": "businessPartner.names[0].value",
"valueA": "cdq",
"valueB": "cdq",
"similarity": 0.8
},
{
"jsonPath": "businessPartner.addresses[0].thoroughfares[0].value",
"valueA": "lukasstrasse 4",
"valueB": "lukasstrasse 4",
"similarity": 0.7
},
{
"jsonPath": "businessPartner.addresses[0].localities[0].value",
"valueA": "st gallen",
"valueB": "st glan",
"similarity": 0.5510204081632653
}
]
}
},
"linkStatus": "INFERRED"
}
]
}Each response from the /entityresolution/entitymatchinglinks endpoint consists of the following elements:
status: an object that contains information about the success or failure of handling the request.limit: a value that reflects the same value as in the corresponding request.values: an array that contains the list of link objects (might be empty). Each object provides the following key elements:id: the unique identifier of the link.storageId: the unique identifier of the storage that contains data processed by a Duplicate Guard Monitor instance.dataMonitorId: the unique identifier of a Duplicate Guard Monitor instance.createdAt: the date on which the link was created.createdBy: the user who created the link; usually, this is the user who created the monitor.modifiedAt: if a link was modified, this date differs from thecreatedAtfield; otherwise, it is the same.entityA: the first part of the link (for example, a Business Partner). It contains:dataSourceId: the unique identifier of the data source from which this Business Partner originates.businessPartnerId: the unique identifier created at CDQ for the Business Partner that was upserted (loaded into CDQ storage).externalId: the identifier of a Business Partner that is unique on the customer's side.
entityB: the second part of the link (for example, a Business Partner). It contains:dataSourceId: the unique identifier of the data source from which this Business Partner originates.businessPartnerId: the unique identifier created at CDQ for the Business Partner that was upserted (loaded into CDQ storage).externalId: the identifier of a Business Partner that is unique on the customer's side.
confidence: an explanation of the similarity score. It contains the following data:overallScore: the similarity score value.status: the status of the match —MATCHorMAYBE_MATCH.explanation: a detailed explanation of each attribute considered when calculating theoverallScorevalue. It consists of the following elements:jsonPath: the JSON path of the attribute that was checked.valueA: the first value used in the comparison, which belongs to theentityAobject.valueB: the second value used in the comparison, which belongs to theentityBobject.similarity: the calculated value obtained from comparingvalueAandvalueBusing the algorithm specified in the configuration for this particularjsonPathattribute.
linkStatus: the status of the link (INFERRED,ASSERTED, orRETRACTED).
Each Duplicate Guard Monitor instance can have the following states in which different things are being accomplished:
Initialization: when a user creates a monitor it automatically starts initiating the process of deduplication based on the given configuration. In this state all Business Partners are checked in order to find the links between a Business Partner and its potential duplicates. In case, that all Business Partners were analyzed the monitor changes its status in to theMonitoringstate.Monitoring: when the initialization is accomplished the Duplicate Guard Monitor continuously monitors for new or updated Business Partners in the Data Mirror. Any change in a Business Partner attributes triggers checks and, as a result, Duplicate Guard Monitor searches for new potential duplicates. In this case new links might be created while others can be removed (it depends on the changes done in Business Partner data attributes as well as on the applied matching configuration). Also, any deletion of a Business Partner will affect all the links in which it was present. In this case those links will be removed. Therefore, the number of duplicates will be smaller.Reevaluation: this is the state in which all Business Partners are reevaluated once again. Certain events can trigger a reevaluation of the data being monitored. One trigger is the change of the configuration of the Duplicate Guard Monitor. Either replacing it completely or just updating the already attached configuration. Another trigger is that the previous attempt to execute the monitor failed or was incomplete. In such a case it is expected that the system periodically tries to reevaluate the data. In case that configuration was modified, all previously existed links are removed and for each Business Partner the monitor is searching for its potential duplicates. Please keep in mind that links reviewed by a user and changed to statusASSERTEDorRETRACTEDare never removed from the Link Database. A user is unable to delete the configuration attached to the Duplicate Guard Monitor. If the user wants to delete the configuration then the Duplicate Guard Monitor needs to be deleted first.
The new Duplicate Guard set of tools was designed and implemented in order to provide a more robust solution for identifying duplicates with large volumes of data in mind. As a result the matching engine was revised to enable storages with large volumes of records, i.e. up to 5 Mln records. Moreover, it uses MongoDB collection to store the Links instead of an in-memory link database which highly limited the number of records available for processing. The main differences between old Duplicate Matching apps and the new Duplicate Guard are the following:
- Completely new matching engine that works in the monitor-based way.
- New JSON-based configuration that is easy to understand and change - way better than the previous XML-based solution.
- New application for handling Matching Configurations - Duplicate Guard Configurator.
- New format of reports based on links between Business Partners data.
- New structure of response.
- Newly defined set of comparators and cleaners (limited in comparison to the previous solution).
- All available settings are listed in the form of API responses.
- Continuous way of delivering results (monitor-based approach in comparison to the old, job-based approach).
- New way of browsing links between Business Partners (not implemented yet).
- More robust and future-proof implementation.
Finding duplicates of Business Partners is a really demanding and time-consuming task. However, thanks to Duplicate Guard solution we are able to identify potential duplicates in an easy to use and manageable way. Moreover, results are always up-to-date and available in the easy to understand way. Additionally, since the detection and management of duplicates is fully automated in Duplicate Guard Monitor it reduces manual intervention, ensuring cleaner and more reliable datasets. As a result, maintenance of Business Partners data integrity can be done with minimal effort.
Click here to expand Appendixes
Cleaners transform or normalize data before it is effectively compared by the duplicate analysis algorithm. So a cleaner's job is to make comparison easier by removing from data values all variations that are not likely to indicate genuine differences. For example, a cleaner might strip everything except digits from a zip code. Or, it might normalize and lowercase addresses. Or translate dates into a common format.
All the cleaners that we currently support in Duplicate Guard can be found under the following endpoint: /entityresolution/cleaners which results in the following list:
Regular Expression Cleaner.
This cleaner uses regular expressions to do the cleaning. Basically, it matches the input against the regular expression it has given, and returns the part matching group number 1 (by default), or the given group. If the expression does not match, it returns null. It takes the following arguments (parameters):
regexp: The regular expression to use. Must contain at least one group.groupno: The number of the group to extract. 1 by default.discard: Boolean value to indicate if the attribute should be discarded when the regular expression does not match. Changes the behaviour so the cleaner instead discards the matching group and keeps the rest of the string.discardAllGroup: Boolean value to discard all found groups (true) or not (false).
Punctuations Cleaner.
Removes punctuation marks from a given string. For example, from the following string: "Just as it. Is." the resulting string should be as follows: "Just as it Is".
Digits Only Cleaner.
This cleaner removes everything which is not a digit, and could be used to clean a postal code. For example, from the following string "This is post code
12345." we should obtain the resulting string like this:12345.Lower Case Normalizer.
The most widely used cleaner for string values. It lowercases all letters, removes whitespaces at beginning and end, and normalizes whitespace characters in between tokens. It also removes accents, turning é into e, and so on. In case of the following string:
" And this is multiple spaces now and LOWERCASE STRING"
we should obtain the resulting value: "and this is multiple spaces now and lowercase string".Legal Form Cleaner.
Special cleaner for Business Partner names. The cleaner identifies a legal form in the input string and cuts the part BEFORE the legal form. To well-recognize legal forms, the cleaner needs to get some country information. For example, in CDQ AG Factory St. Gallen, AG is identified as legal form and only CDQ is used for matching. As a
configPropertyparameter appropriate country short name value needs to be provided, for example:$.addresses[0].country.shortName.
A Comparator can compare two string values and produce a similarity measure between 0.0 (meaning completely different) and 1.0 (meaning exactly equal). These are used because we need something better than simply knowing whether two values are the same or not. Also, different kinds of values must be compared differently, and comparison of complex strings like names and addresses is a whole discipline in itself.
The list of available comparators that is supported by Duplicate Guard can be found under the following endpoint: /entityresolution/comparators which results in the following list:
Jaro-Winkler distance.
The Jaro-Winkler similarity measure, which many studies have found to be the best available general string comparator for deduplication. This comparator can be best used for short strings like given names and family names. Not so good for longer, general strings.
Exact Comparator.
Reports
0.0if the values are not equal and1.0if they are equal.Levenshtein distance.
It uses Levenshtein edit distance to compute the similarity between two strings. Basically, it measures the number of edit operations needed to get from the first string to the second one.
Longest Common Substring Comparator.
Finds the longest common substring of 2 given strings. It does not merely find the longest common substring, but does so repeatedly down to a minimal substring length.
Damerau–Levenshtein Comparator.
It uses Damerau–Levenshtein distance to compute the similarity between two strings. It differs from the classical Levenshtein distance by including transpositions among its allowable operations in addition to the three classical single-character edit operations (insertions, deletions and substitutions). As a result it calculates the minimum number of all those operations (insertions, deletions or substitutions of a single character, or transposition of two adjacent characters) required to change one string into the other. It is useful for identifying typographical errors involving adjacent character swaps.
Dice similarity coefficient Comparator.
Computes the Dice coefficient of two tokenized strings. Tokens are compared using exact comparison by default, but any comparator can be used to compare tokens.
Q-Gram Comparator.
Uses q-grams comparison. It seems to be similar to Levenshtein, but a bit more eager to consider strings the same and doesn't care in what order tokens are comprised by the strings (with
BASICtokenizer). So for strings consisting of tokens that may be reordered it may be a better alternative than Levenshtein, e.g. Hotel Lindner vs. Lindner Hotel. It takes the following arguments (parameters):q: The value of q, that is, the size of the q-grams. Default:2.formula: Which formula to use to compare sets of q-grams from the two strings. Alternatives:OVERLAP,DICE,JACCARD. Default:OVERLAP.tokenizer: Determines what kind of q-gram to produce. Alternatives:BASIC,POSITIONAL(includes the position of the q-gram), andENDS(likeBASIC, but includes first and last characters). Default:BASIC.
Weighted Levenshtein distance.
A configurable version of Levenshtein where edit operations can be assigned different weights. Very useful in cases where numbers make up part of the string, and differences in the numbers matter more than differences in letters. Addresses are one example of this, because Main Street 12 and Main Street 14 are very different.
The list of available search attributes that is supported by Duplicate Guard can be found under the following endpoint: /entityresolution/searchattributepaths which results in the following list:
$.externalId,$.names[].value,$.identifiers[].value,$.addresses[].externalId,$.addresses[].careOf.value,$.addresses[].country.shortName,$.addresses[].country.value,$.addresses[].administrativeAreas[].shortName,$.addresses[].administrativeAreas[].value,$.addresses[].postCodes[].value,$.addresses[].thoroughfares[].value,$.addresses[].thoroughfares[].number,$.addresses[].localities[].value
Those attributes are important when trying to find possible candidates for duplicate matching. Based on search attributes our duplicate matching engine tries to find the best candidates to be considered as duplicates. It depends strongly on the pattern Business Partner and given search attributes (and their indexed values). The more search attributes are given the more adequate candidates we will find. However, in this case we may miss some candidates that can contain wrong values but are still duplicates. Usually, country and name of a Business Partner are enough. If we want to be more precise we can add a thoroughfare (street) and locality (city).
The list of available matching attributes that is supported by Duplicate Guard can be found under the following endpoint: /entityresolution/attributepaths which results in the following list:
businessPartner.id,businessPartner.createdAt,businessPartner.lastModifiedAt,businessPartner.dataSource,businessPartner.externalId,businessPartner.disclosed,businessPartner.names[],businessPartner.names[].value,businessPartner.names[].shortName,businessPartner.names[].type.name,businessPartner.names[].type.url,businessPartner.names[].type.technicalKey,businessPartner.names[].language.name,businessPartner.names[].language.technicalKey,businessPartner.legalForm.name,businessPartner.legalForm.url,businessPartner.legalForm.language.name,businessPartner.legalForm.language.technicalKey,businessPartner.identifiers[],businessPartner.identifiers[].value,businessPartner.identifiers[].issuingBody.name,businessPartner.identifiers[].issuingBody.url,businessPartner.identifiers[].issuingBody.technicalKey,businessPartner.identifiers[].type.name,businessPartner.identifiers[].type.url,businessPartner.identifiers[].type.technicalKey,businessPartner.externalContext.identifiers[],businessPartner.externalContext.identifiers[].value,businessPartner.externalContext.identifiers[].type.technicalKey,businessPartner.categories[],businessPartner.categories[].name,businessPartner.categories[].url,businessPartner.categories[].technicalKey,businessPartner.status.type.name,businessPartner.status.type.url,businessPartner.status.type.technicalKey,businessPartner.profile.minorityIndicator.value,businessPartner.profile.classifications[],businessPartner.profile.classifications[].value,businessPartner.profile.classifications[].code,businessPartner.profile.classifications[].type.name,businessPartner.profile.classifications[].type.url,businessPartner.addresses[],businessPartner.addresses[].id,businessPartner.addresses[].externalId,businessPartner.addresses[].cdqId,businessPartner.addresses[].types[],businessPartner.addresses[].types[].name,businessPartner.addresses[].types[].url,businessPartner.addresses[].types[].technicalKey,businessPartner.addresses[].careOf.value,businessPartner.addresses[].contexts[],businessPartner.addresses[].contexts[].value,businessPartner.addresses[].country.value,businessPartner.addresses[].country.shortName,businessPartner.addresses[].administrativeAreas[],businessPartner.addresses[].administrativeAreas[].value,businessPartner.addresses[].administrativeAreas[].shortName,businessPartner.addresses[].administrativeAreas[].type.name,businessPartner.addresses[].administrativeAreas[].type.url,businessPartner.addresses[].administrativeAreas[].type.technicalKey,businessPartner.addresses[].administrativeAreas[].language.name,businessPartner.addresses[].administrativeAreas[].language.technicalKey,businessPartner.addresses[].postCodes[],businessPartner.addresses[].postCodes[].value,businessPartner.addresses[].postCodes[].type.name,businessPartner.addresses[].postCodes[].type.url,businessPartner.addresses[].postCodes[].type.technicalKey,businessPartner.addresses[].localities[],businessPartner.addresses[].localities[].value,businessPartner.addresses[].localities[].shortName,businessPartner.addresses[].localities[].type.name,businessPartner.addresses[].localities[].type.url,businessPartner.addresses[].localities[].type.technicalKey,businessPartner.addresses[].localities[].language.name,businessPartner.addresses[].localities[].language.technicalKey,businessPartner.addresses[].thoroughfares[],businessPartner.addresses[].thoroughfares[].value,businessPartner.addresses[].thoroughfares[].name,businessPartner.addresses[].thoroughfares[].shortName,businessPartner.addresses[].thoroughfares[].direction,businessPartner.addresses[].thoroughfares[].number,businessPartner.addresses[].thoroughfares[].type.name,businessPartner.addresses[].thoroughfares[].type.url,businessPartner.addresses[].thoroughfares[].type.technicalKey,businessPartner.addresses[].thoroughfares[].language.name,businessPartner.addresses[].thoroughfares[].language.technicalKey,businessPartner.addresses[].premises[],businessPartner.addresses[].premises[].value,businessPartner.addresses[].premises[].shortName,businessPartner.addresses[].premises[].number,businessPartner.addresses[].premises[].type.name,businessPartner.addresses[].premises[].type.url,businessPartner.addresses[].premises[].type.technicalKey,businessPartner.addresses[].premises[].language.name,businessPartner.addresses[].premises[].language.technicalKey,businessPartner.addresses[].postalDeliveryPoints[],businessPartner.addresses[].postalDeliveryPoints[].value,businessPartner.addresses[].postalDeliveryPoints[].shortName,businessPartner.addresses[].postalDeliveryPoints[].number,businessPartner.addresses[].postalDeliveryPoints[].language.name,businessPartner.addresses[].postalDeliveryPoints[].language.technicalKey,businessPartner.addresses[].postalDeliveryPoints[].type.name,businessPartner.addresses[].postalDeliveryPoints[].type.url,businessPartner.addresses[].postalDeliveryPoints[].type.technicalKey,businessPartner.addresses[].geographicCoordinates.latitude,businessPartner.addresses[].geographicCoordinates.longitude,businessPartner.types[],businessPartner.types[].url,businessPartner.types[].name,businessPartner.types[].technicalKey,businessPartner.record
Those attributes can be used to compare values that are present in two Business Partners that are expected to be duplicates. Each attribute path can have its own algorithm and cleaner that need to be provided in a duplicate matching configuration. Usually, few attributes are enough (like Business Partner's name, city, street or country) but in some special cases (finding the same company's name in different countries) choice of completely different attributes might be useful for finding properly duplicated Business Partners.
We are constantly working on providing an outstanding user experience with our products. Please share your opinion about this tutorial!